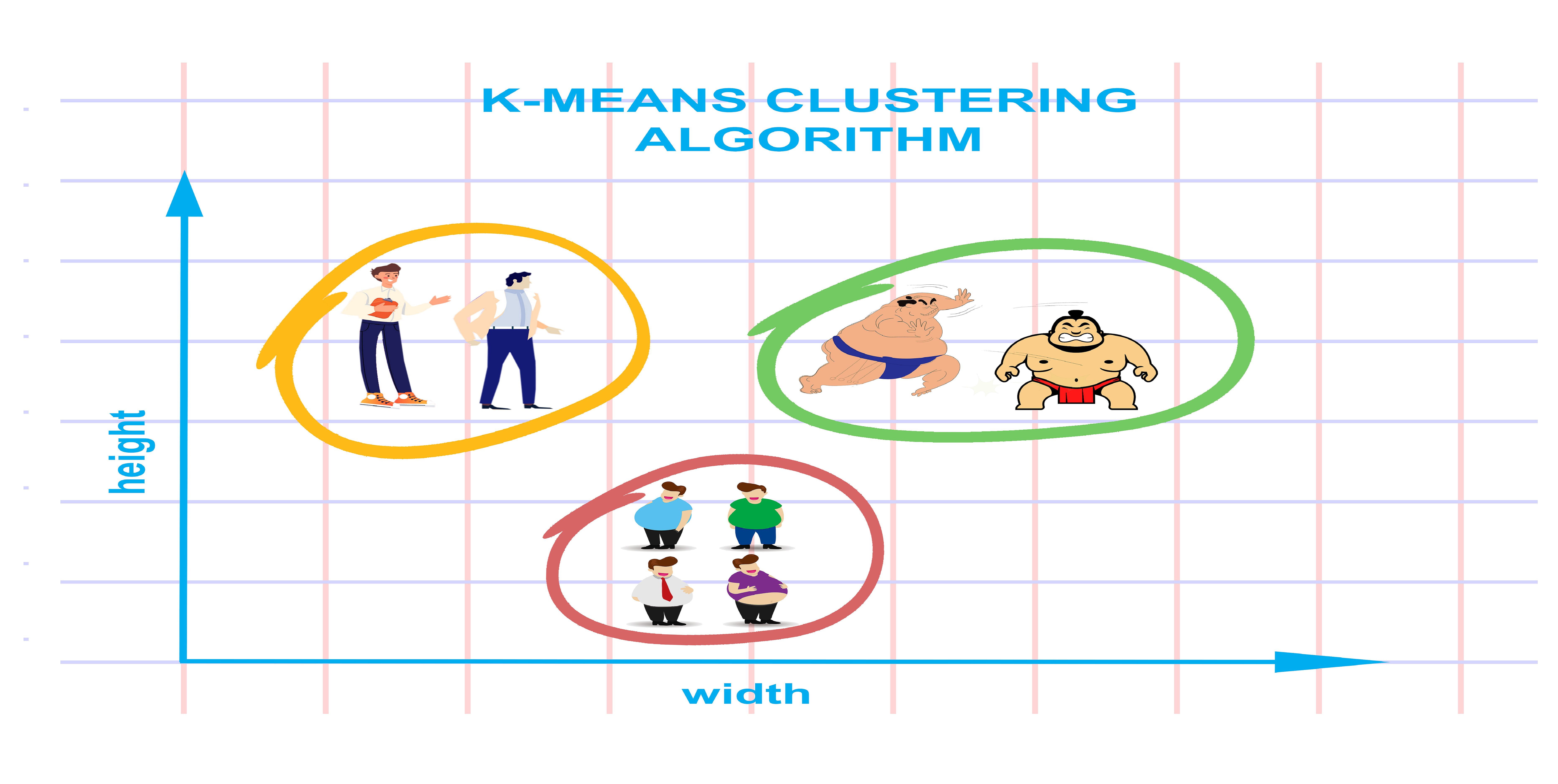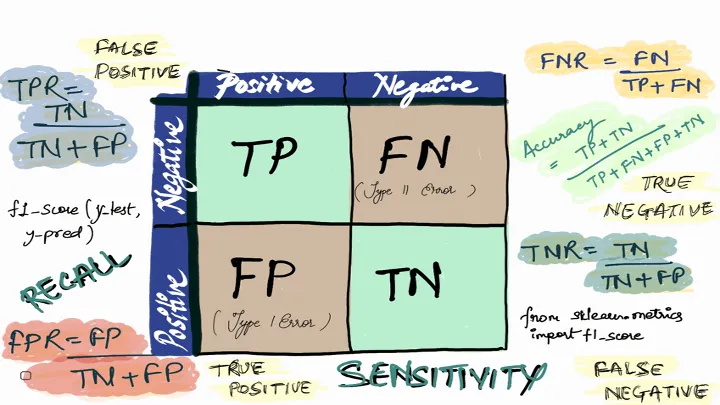
Classification Evaluation Metrics in Machine Learning
Classification metrics such as precision, recall, sensitivity, and specificity offer a comprehensive view of model performance, especially in imbalanced datasets. Real-life examples from fraud dete...