Getting Started with NLP | A Journey from RNNs to Transformers
Explore the evolution of Natural Language Processing, from early sequence models like RNNs to the revolutionary Transformer architecture. Learn about tokenization, embeddings, and other fundamental concepts driving modern NLP techniques.

Natural language processing is a sub-branch of artificial intelligence that works to improve the communication between humans and the machines. Although it has become popular today with chatbots like ChatGPT and voice assistants like Siri, it has actually been affecting our lives as a field much earlier. For example, the translation process from one language to another, which Google Translate does, is one of the problems solved by natural language processing.
Natural language processing methods have continued to develop and increase over time. The chronological order of deep learning-based NLP architectures from the oldest to the newest is as follows: RNN, LSTM, GRU, BiLSTM, Transformer, LLM.
Sequence Models
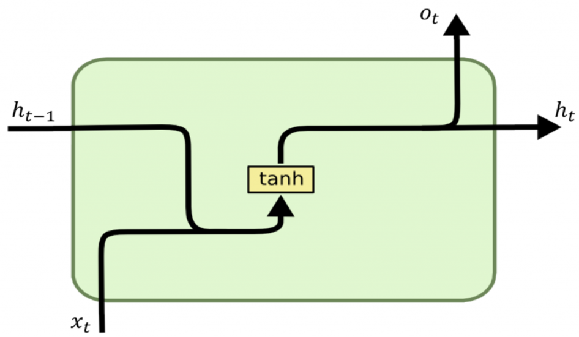 Simple RNN Cell. Image by [4]
Simple RNN Cell. Image by [4]
Recurrent Neural Networks is one of revolutionary models that can work on sequential data. It is an artificial neural network architecture that allows predictions about the future using information from the previous time series. It has been used for tasks such as speech recognition and text generation, but it has some disadvantages. For example, when the input is too long, problems such as forgetting previous information and vanishing gradient are encountered.
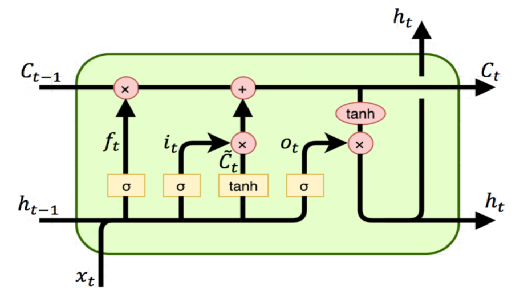 LSTM Cell. Image by [4]
LSTM Cell. Image by [4]
 Operations. Image by [4]
Operations. Image by [4]
Long-Short Term Memory (LSTM) architecture, is supported by several mathematical gates and memory cells in addition to the RNN architecture. These gates ensure that some of the previous information is forgotten and updated with new information, while the memory cell ensures that the previous information is retained. In this way, only useful information related to the past is retained, and the vanishing gradient problem for longer time series can be partially solved.
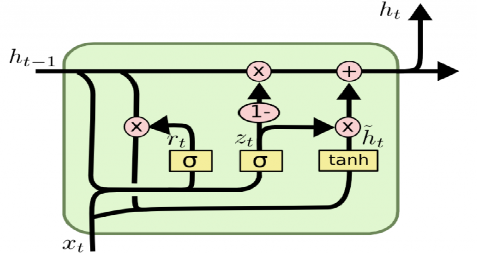 GRU Cell. Image by [4]
GRU Cell. Image by [4]
Gated Recurrent Unit (GRU) architecture, is very similar to LSTM but uses different and fewer mathematical gates. The same advantages gained when moving from RNN to LSTM apply to this. By changing the activation functions in the gate, different and sometimes better results can be obtained.
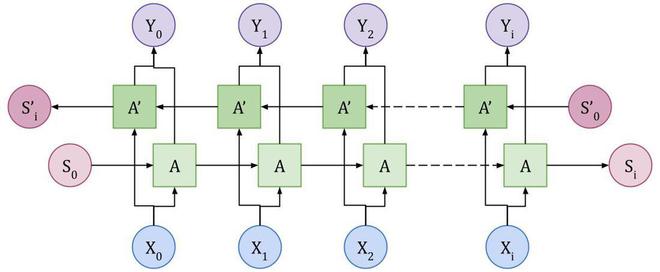 Bidirectional LSTM Architecture.
Bidirectional LSTM Architecture.
Bidirectional LSTM, in addition to the LSTM architecture, a two-way training process is implemented, allowing it to learn better by looking at both past and future words. It is much more successful than normal LSTMs for tasks such as Named Entity Recognition and Part of Speech.
 Seq2Seq Paper.
Seq2Seq Paper.
Encoder-Decoder architecture is a very powerful structure in seq2seq tasks. In this structure, architectures such as LSTM and RNN that can perform seq2seq tasks are used in both parts. The structures can be the same or can be differentiated, they are customized according to the tasks. On the encoder side, the input sequence is processed and the input is encoded and a context vector is created. This context vector produced on the decoder side is taken as input and decoded and the output sequence is created. In classical encoder-decoder architectures, the input sequence, context vector and output sequence shapes are fixed. This brings us some parameter restrictions that we need to determine beforehand. For example, when translating from one language to another, we need to give a rule such as you can produce a maximum of 5 words of output with a 3-word input. This causes semantic loss.
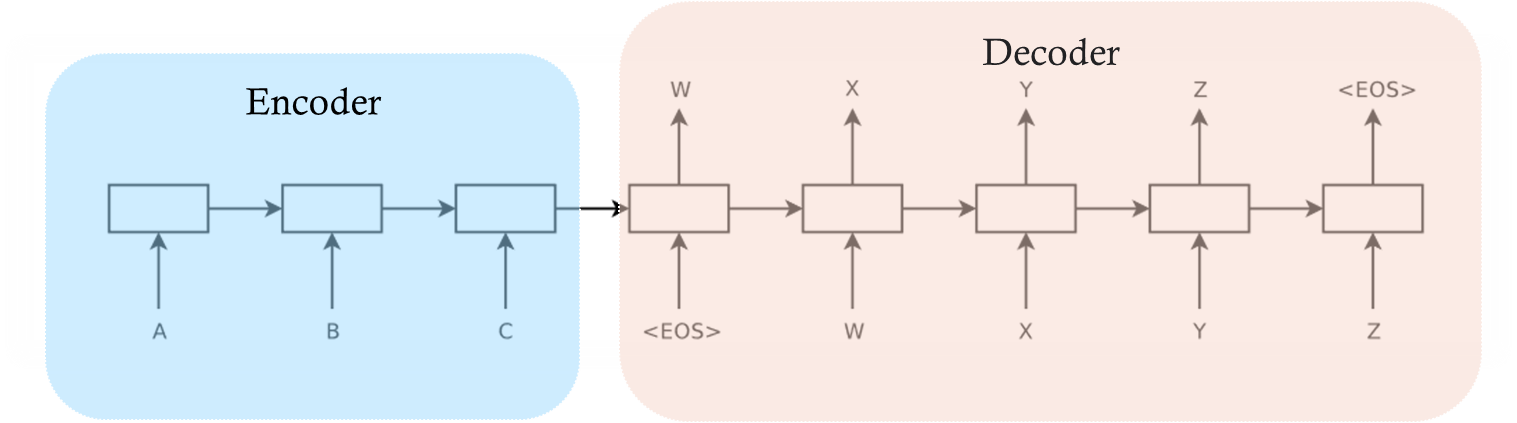 Encoder-Decoder Architecture.
Encoder-Decoder Architecture.
 Attention is All You Need Paper.
Attention is All You Need Paper.
With the Transformer architecture released in 2017, a solution was found to this problem. This architecture is basically based on the Attention mechanism. In another article, I will explain the following Transformer architecture step by step and code it from scratch with pytorch.
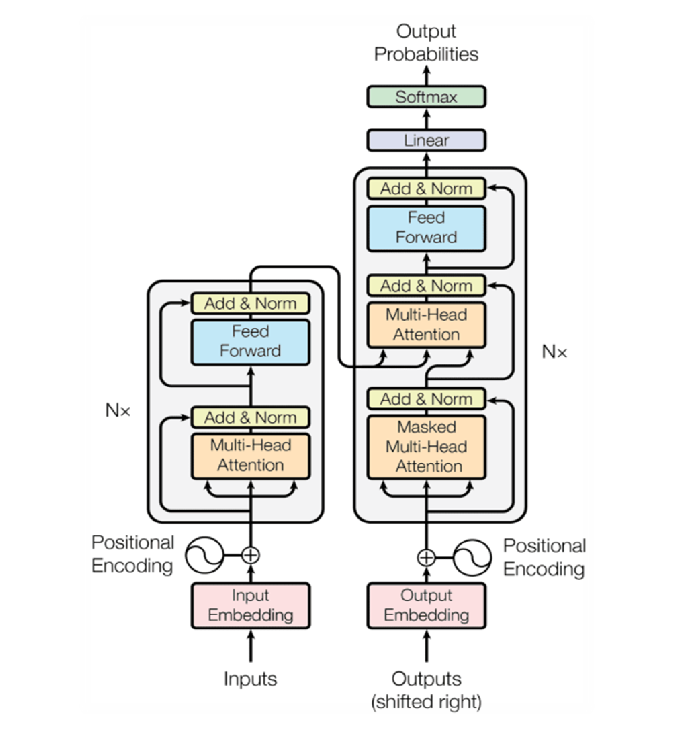 Transformer Architecture
Transformer Architecture
The Transformer architecture above has been diversified in different ways and is used in today’s models with architectures such as BERT, T5, GPT.
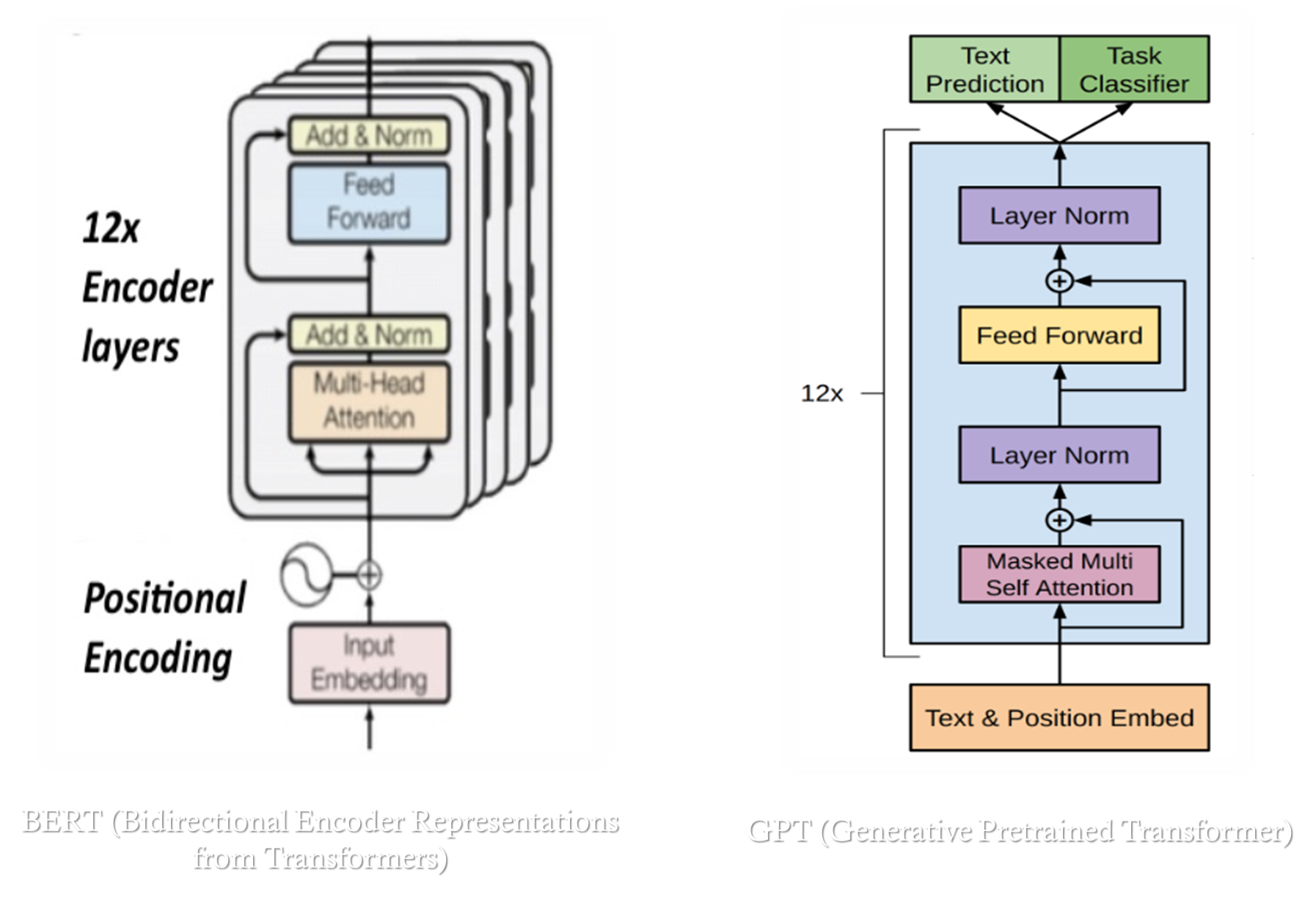
Types of Sequence Models
NLP models handle sequences of data in different ways, depending on the task. Here’s a quick overview of how these sequences are structured:
- One-to-One: A single input produces a single output.(e.g., Image classification)
- One-to-Many: A single input generates a sequence of outputs.(e.g., Image captioning,recommendation)
- Many-to-One: Multiple inputs generate a single output.(e.g.,Sentiment analysis, traffic, next sale)
- Many-to-Many: Both input and output are sequences.(e.g., Machine translation, chatbots, qa,llm, text summarization, speech recognition)
Key NLP Concepts
When working with language data, there are several basic concepts you need to understand.
Tokenization
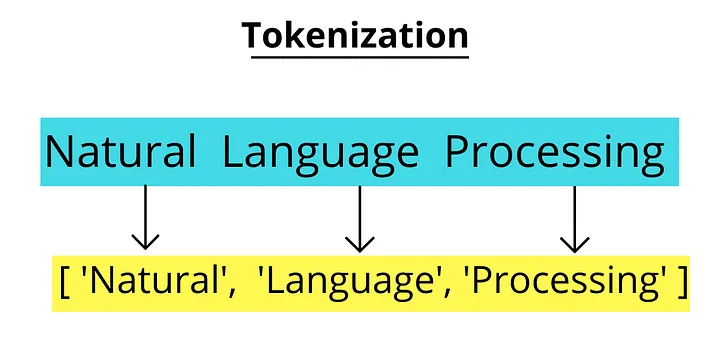
Tokenization splits text into smaller pieces, usually words or subwords. It’s one of the first steps in processing text, as models work with these smaller units rather than the full sentence or paragraph.
Encoding
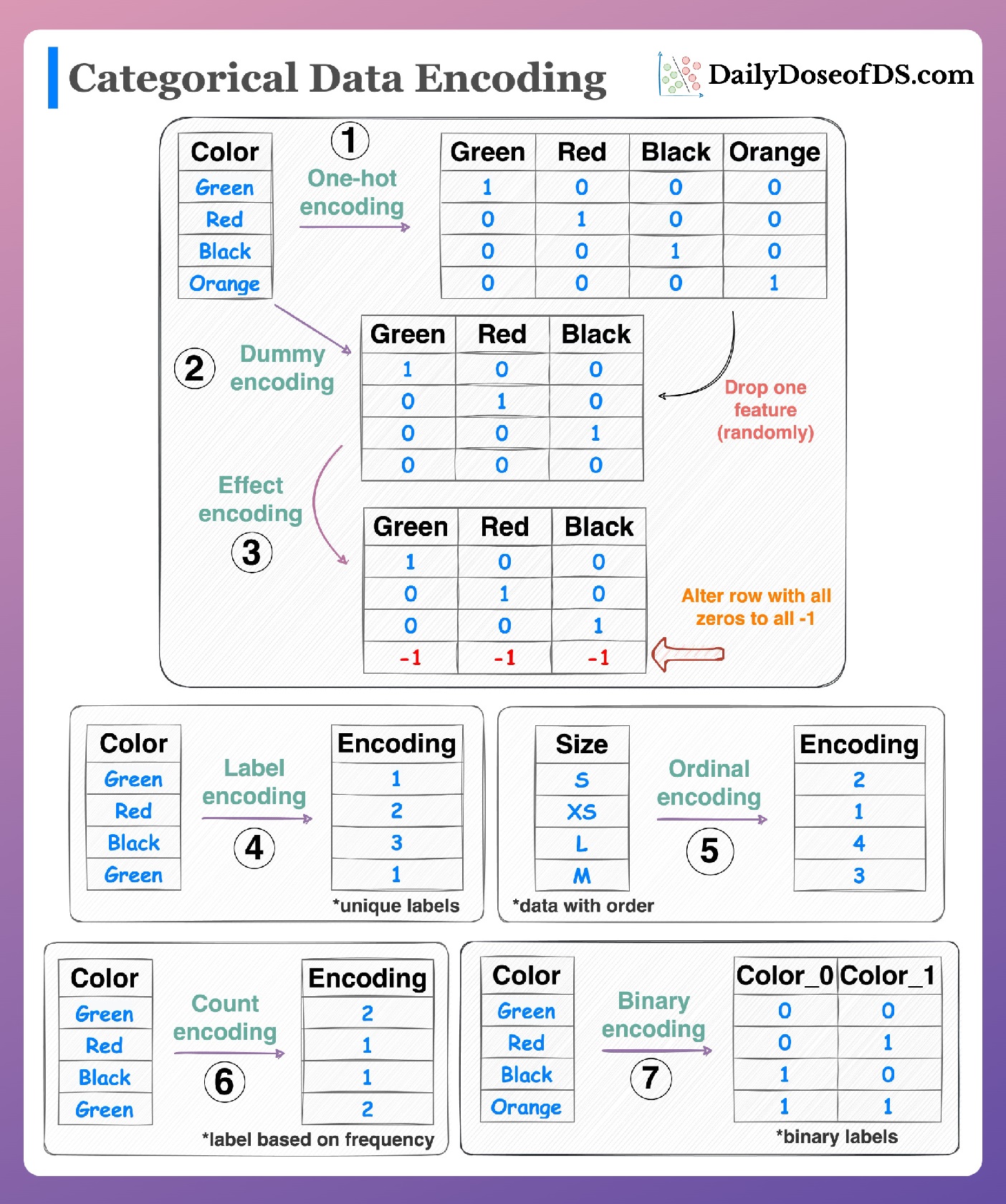 Encoding styles. Image by Avi Chawla [6]
Encoding styles. Image by Avi Chawla [6]
Encoding transforms text data into numerical values that models can process. Common encoding methods include one-hot encoding and integer encoding, though they don’t capture the meaning or relationships between words.
Embeddings
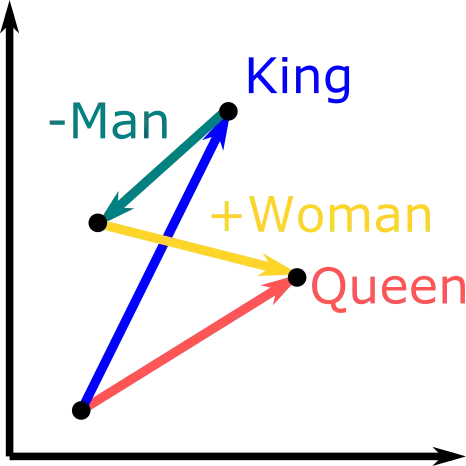 Common Embedding Example
Common Embedding Example
Embeddings represent words as dense vectors in a multi-dimensional space, where semantically similar words are closer together. Word2Vec and GloVe are common methods for generating word embeddings.
Lemmatization and Stemming
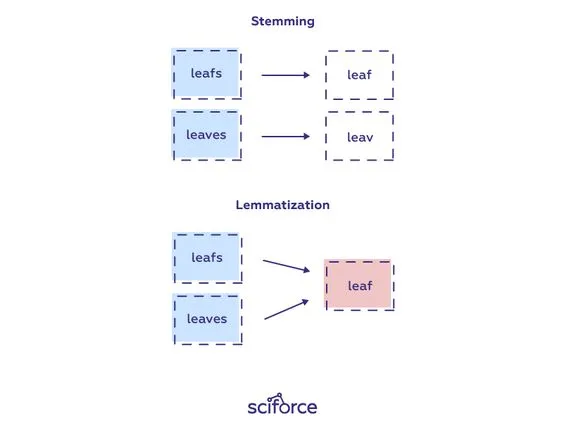 Lemmatization & Stemming. Image by Pinterest
Lemmatization & Stemming. Image by Pinterest
Both techniques are used to reduce words to their base form.
- Stemming: Reduces words to their root form by chopping off suffixes (e.g., “running” becomes “run”).
- Lemmatization: Converts words to their dictionary form, considering the context (e.g., “better” becomes “good”).
Bag of Words (BoW)
Bag of Words is a simple method that represents text as a collection of words, ignoring order and context. Each word is associated with a frequency count, which helps in identifying key terms, but it doesn’t capture meaning or relationships.
TF-IDF(Term Frequency- Inverse Document Frequency)
TF-IDF improves upon BoW by weighing words based on how important they are in a document relative to how common they are across all documents. Words that are frequent in a single document but rare across others are given more importance.
Word2Vec
Word2Vec is an embedding technique that represents words in a continuous vector space. It captures the relationships between words based on their surrounding words, making it useful for semantic tasks like similarity detection and analogy solving. There are two common techniques, CBOW and n-skip gram. In both techniques, a certain window size is determined and a supervised dataset is created. In CBOW, the relationship between the middle word and the surrounding words is examined, in skip gram, the relationship between the surrounding words and the middle word is examined. Last but not least, there are other techniques like word2vec such as GloVe, FastText etc.
Conclusion
NLP has come a long way, evolving from simple models like RNNs to complex architectures like Transformers. Each new model improved upon the limitations of the previous one, leading to the powerful Large Language Models we have today. With these advances, computers are now capable of understanding and generating language at levels that were once thought impossible.
NLP is now an integral part of modern technology, enabling everything from search engines to virtual assistants. The field will continue to evolve, and with it, the ways we interact with machines will become more seamless and natural.
References
- Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. “Sequence to sequence learning with neural networks.” NIPS 2014.
- Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. “Neural machine translation by jointly learning to align and translate.” ICLR 2015.
- Ashish Vaswani, et al. “Attention is all you need.” NIPS 2017.
- Understanding LSTMS, Christopher Olah .
- Wikidocs; LSTM,GRU,RNN
- 7 Must-know Techniques For Encoding Categorical Feature, Avi Chawla