DeepSeek-R1 İnceleme
Geçtiğimiz haftalarda OpenAI’nın o1–127 modeli ile yarışabilen DeepSeek-R1 modeli açık kaynaklı olarak yayınlandı. Bu ölçüde başarılı bir modelin hem model ağırlıklarıyla birlikte hem de makalesiyle yayınlanması şüphesiz ki açık kaynak için güzel bir gelişme olduğunu düşünüyorum, umarım bu tarz çalışmaların devamı da gelir. DeepSeek-R1, araştırmacıların açıklamasına göre diğer açık/kapalı LLM’lere kıyasla çok az daha maliyet(~%95) ve daha az süre ile(~x11 gpu saati) eğitilmiş. DeepSeek-R1 modelinin eğitiminde SFT ile birlikte geniş ölçekli bir Reinforcement Learning (GRPO) kullanılıyor. Ancak DeepSeek-R1-Zero modelinin eğitiminde sadece Reinforcement Learning (GRPO) kullanılıyor.
Geçtiğimiz haftalarda OpenAI’nın o1–127 modeli ile yarışabilen DeepSeek-R1 modeli açık kaynaklı olarak yayınlandı. Bu ölçüde başarılı bir modelin hem model ağırlıklarıyla birlikte hem de makalesiyle yayınlanması şüphesiz ki açık kaynak için güzel bir gelişme olduğunu düşünüyorum, umarım bu tarz çalışmaların devamı da gelir. DeepSeek-R1, araştırmacıların açıklamasına göre diğer açık/kapalı LLM’lere kıyasla çok az daha maliyet(~%95) ve daha az süre ile(~x11 gpu saati) eğitilmiş. DeepSeek-R1 modelinin eğitiminde SFT ile birlikte geniş ölçekli bir Reinforcement Learning (GRPO) kullanılıyor. Ancak DeepSeek-R1-Zero modelinin eğitiminde sadece Reinforcement Learning (GRPO) kullanılıyor.
Makaleyi incelediğinizde 3 farklı temel model ve distilled modeller ile karşılaşıyoruz:
- DeepSeek-V3-Base[2]: DeepSeek tarafından SFT ve RL ile eğitilmiş base model. Bu model de oldukça başarılı ve diğer modellerin eğitiminde foundation model olarak kullanılıyor,
- DeepSeek-R1-Zero[1] : Deepseek-V3-Base üzerine sadece RL pipeline’ını uygulanarak eğitilen model,
- DeepSeek-R1[1]: DeepSeek-V3-Base üzerine SFT ve RL ile birlikte eğitilmiş model,
- DeepSeek-R1-Distilled-…[1] : Distilled modeller, DeepSeek-R1 modelini eğittikleri pipeline’ın aynısı ile open-source diğer modelleri fine-tune ediyorlar ve bu modeli distilled olarak adlandırıyorlar, (örn. Qwen 2.5B alıp, DeepSeek-R1’in eğitim pipeline’ının aynısını uygulamışlar)
Reinforcement Learning Algorithm
RL adımındaki maliyeti azaltmak amacıyla Group Relative Policy Optimization (GRPO)[3] kullanılmış. Matematiksel kısımlara çok detaylı değinmeyeceğim ancak makale içerisinde aşağıdaki gibi belirtilmiş;

Prompt
Bu çalışmada hoşuma giden kısımlardan birisi de prompt’un olabildiğince basit, anlaşılır ve kısa olması. Aşağıdaki prompt taslağına uygun olarak hazırlanan CoT’ler(Chain of Thoughts) ile eğitimler gerçekleştirilmiş. Özellikle prompt içerisinde modelin önyargılı bir şekilde davranmasını engellemek için detaylı veya kısıtlayıcı instruction kullanmaktan kaçınılmış ve bu yönlendirmeler için RL adımına güvenilmiş.
 DeepSeek-R1-Zero Prompt Template
DeepSeek-R1-Zero Prompt Template
Ödüllendirme
Eğitim kısmında modelin ödüllendirmelerini yapmak için 3 farklı temel ödül koşulu belirlemişler:
- Doğruluk Ödülleri: Cevapların beklenen cevap olup olmamasına göre ödüllendirme yapılmış ,
- Format ödülleri: Doğruluk kısmına ek olarak, cevapların doğru formatta gelip gelmediğine göre ödüllendirme yapılmış. Özellikle deepseek’in deepthink özelliği için
- Dil tutarlılığı ödülleri : DeepSeek-R1-Zero sorulan sorulara doğru yanıtlar verse bile, okunurluk açısından ve cevaplarda farklı dilleri birbirine karıştırması sebebiyle bu madde sonraki eğitimlerde DeepSeek-R1 ve distilled modeller için ödül mekanızmasına eklenmiş
Bu bilgilere göre dataset, prompt templatine uygun olacak şekilde formatlanarak, belirtilen GRPO ve ödül kurallarına göre RL süreciyle 8000 adımdan fazla eğitilerek DeepSeek-R1-Zero modelini oluşturmuşlar. DeepSeek-R1-Zero özellikle reasoning tasklarında makalede paylaşılan sonuçlara göre oldukça başarılı olduğu ve o1 ile yarışabildiği görülüyor
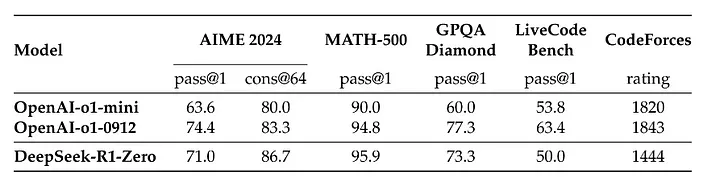 DeepSeek-R1-Zero Başarım vs OpenAI-o1 Modelleri Başarım
DeepSeek-R1-Zero Başarım vs OpenAI-o1 Modelleri Başarım
RL eğitiminde 8000 den fazla adım eğitim yapıldığı söylense de diğer parametreler veya ne kadarlık bir veri kullanıldığından bahsedilmemiş. Ek olarak, araştırmacılar RL’nin öğrenim aşamasında ilginç bir pattern’ini keşfediyorlar: “Aha Moment”. Bu nokta, modelin çözüme doğru bir şekilde yaklaşabildiği zamana denk geliyor. Çalışma içerisinde aşağıdaki gibi bir örnek paylaşılmış:

Büyük ihtimalle verisetini buna uygun bir şekilde hazırlamışlar ki, bu tarz bir reasoning ya da thinking adımı gerçekleşiyor diye düşünüyorum.
DeepSeek-R1
DeepSeek modelleri bazı süreçlerin birkaç farklı tekrarından oluşuyor, eğitim ve modellerin net bir şekilde anlaşılabilmesi için aşağıdaki görseli inceleyebilirsiniz:
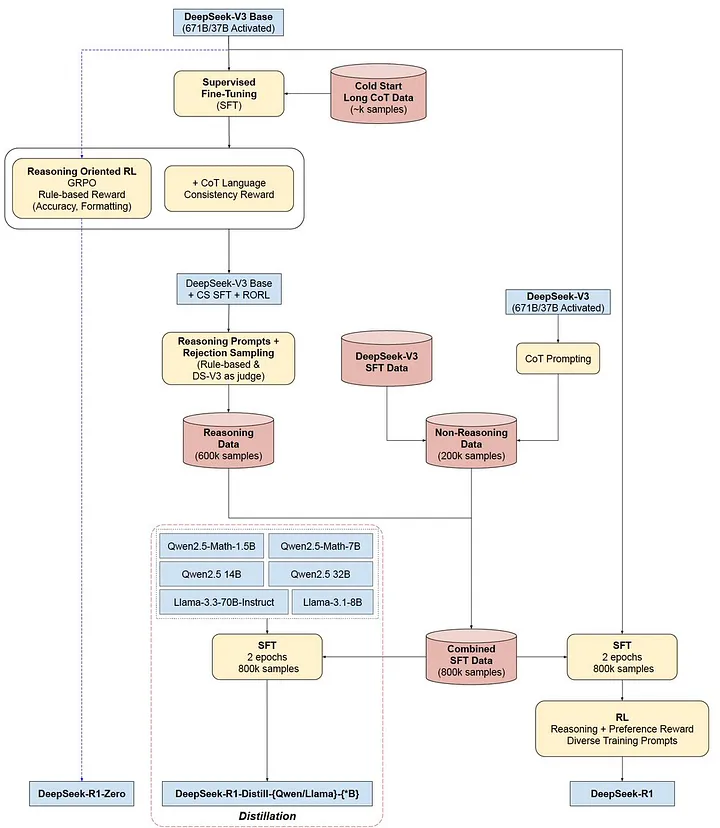 Training Pipeline : DeepSeek-R1-Zero & DeepSeek-R1 & DeepSeek-R1-Distill Models. Image by SirrahChan
Training Pipeline : DeepSeek-R1-Zero & DeepSeek-R1 & DeepSeek-R1-Distill Models. Image by SirrahChan
DeepSeek-R1 modeli, DeepSeek-R1-Zero da olduğu gibi tamamen RL ile eğitilmemiş. RL’den önce DeepSeek-V3-Base modeli belli bir miktarda cold start data (CoT verisi) ile finetune edilmiş ve daha sonra RL adımı uygulanmış. CoT datası hazırlanırken DeepSeek-R1-Zero modeli ile sentetik bir şekilde veriler üretilmiş ve okunabilir bir şekilde formatlanmış. Format olarak; |special_token| <reasoning_process> |special_token| <summary> taslağına uygun olacak şekilde formatlama yapılmış ve daha sonra insanlar tarafından kontroller ve iyileştirmeler yapılmış. Böylece kaliteli bir cold start data oluşturmuş ve DeepSeek-V3-Base’i finetune etmişler. Finetune edilen bu ara model, DeepSeek-R1-Zero eğitiminde kullanılan aynı RL pipeline’ı ile eğitilerek optimize bir ara model oluşturulmuştur. Fark olarak, ödül mekanızmasında dil tutarlılığı ödülleri de eklenmiştir. Böylece cevaplarda dilleri birbirine karıştırma ve okunurluluğun azalması durumunu çözmüşler. Bu model ile diğer modelleri SFT yapacak dataset hazırlanmıştır.
Dataset Hazırlama
Reasoning odaklı RL eğitimi devam ederken, bir sonraki RL turunda SFT verisini toplamak için kontrol noktaları eklemişler. Her kontrol noktasında eğitim verisini birkaç farklı şekilde filtreleyerek formatlamışlar:
— Reasoning Verisi
- Reasoning promptuna uyacak şekilde formatlama,
- Çok uzun paragrafları filtreleme,
- Kod bloklarını filtreleme,
- Cevap içerisinde birden fazla dil ile anlamsız bir metin varsa filtreleme
— Non-Reasoning Verisi:
- DeepSeek-V3’ü eğittikleri veri setindeki kısımların bir kısmını almışlar, basit görevler için (selam, nasılsın vb.) CoT oluşturulmamış.
Gün sonunda, Reasoning için yaklaşık 600k veri, Non-reasoning için yaklaşık 200k veri üreterek toplamda 800k’lık CoT veriseti hazırlamışlar ve bu veri seti ile DeepSeek-V3-Base modelini Fine-tune edip peşine RL süreciyle DeepSeek-R1 modelini elde etmişler.
Distilled Modeller

Elde ettikleri 800k’lık veri ile open-source daki diğer base ya da instruct modelleri sadece SFT(supervise fine-tune) ederek distilled modelleri oluşturmuşlar. Oluşturulan bu modeller kendilerinden daha başarılı olduğu görülmüş.
Sonuç
DeepSeek-R1, sadece RL kullanılarak reasoning veya başka tasklarda başarılı olunabileceğini bize göstermektedir. Ancak bu başarılarda base modelin de ciddi anlamda önemli olduğu unutulmamalıdır. Bununla birlikte, kaliteli bir veri kümesinin modellerin başarısını ciddi oranda etkilediğini tekrar bize göstermektedir. LLM’lerin eğitiminde ve başarımında, post-training ve iterative RL süreçleri üzerine yapılacak çalışmaların faydalı olacağı şeklinde yorumlayabiliriz.
Bu çalışmayı ve modeli açık kaynak olarak yayınladıkları için de araştırmacılara kendi adıma teşekkür ederim.
Referanslar
[1] Liang, W., Guo, D., Yang, D., Zhang, H., & Song, J. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv. https://doi.org/10.48550/arXiv.2501.12948
[2] Liang, W., Guo, D., Yang, D., Zhang, H., & Song, J. (2024). DeepSeek-V3: A High-Performance Mixture-of-Experts Language Model. arXiv. https://doi.org/10.48550/arXiv.2412.19437
[3] Shao, Z., Wang, P., Zhu, Q., Xu, R., & Song, J. (2024). DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv. https://doi.org/10.48550/arXiv.2402.03300