Exploring Apache Cassandra | Core Theoretical Concepts
Cassandra is distributed, de-centralized and fault-tolerant NoSQL database.It is horizontally scalable, low cost, and performs well. It is also a very fast read, open source database.

Introduction
Cassandra is distributed, de-centralized and fault-tolerant NoSQL database. Since Cassandra is distributed, it can be scaled horizontally with high performance. Apart from that, it has a decentralized structure, that is, it has a structure where there are nodes that can continue this role in case a single controller / master node crashes. This gives Cassandra high availability. Lastly, I would like to mention in this short introduction, it is also fault-tolerant thanks to its replication feature.
Data Model
Cassandra is a column-based database is formed nested maps. When we compare with traditional databases, they use keyspace instead of databases and column-family structures instead of tables. Due to their column-based structure, they cause more costly transaction operations than RDBMS. Therefore, they are not very suitable for OLTP, but they can do the reading effectively in terms of quickly accessing the information in the desired columns. In this respect, it is a very suitable database alternative for OLAP.
Keys & Indexes
Cassandra has a primary key as in RDBMS, but does not have a foreign key. Similarly, it has the concept of secondary index. However, the secondary index is not as efficient as the foreign key. At the primary key point, the RDBMS consists of a unique token and is different for each row. In addition, primary keys have a special importance in Cassandra. Because the distribution and storage of data is determined by them.
\[Primary \ Key = Partition \ Key + Clustering \ Key\]
The primary key has the Partition Key, which contains information about how the data will be distributed, and the Clustering Key, which contains information about how this data will be sorted/stored in a node. A Partition function and hashing algorithm are used when creating the Partition Key. This partition algorithm is used to generate a value in the range \([-2^{63}, 2^{63} - 1]\). Today, there are two partitioners that are used most frequently, they differ according to the hashing algorithm they use.
- RandomPartitioner: Generates tokens with MD5 hashing
- Murmur3Partitioner: Generates tokens by Murmur hashing and this is Cassandra’s default setting.
These two methods are often used, but tokens cannot be specifically assigned at certain intervals and do not allow running aggregation queries. Apart from these, there is another Partitioner, ByteOrderedPartitioner, this method generates tokens using hexadecimal representations. As an advantage, aggregation queries can be run and tokens can be generated by giving a specific range. But since many requests are made on some nodes, it causes an unstable system, which we do not want. That’s why ByteOrderedPartitioner is no longer preferred.
Basic Structure
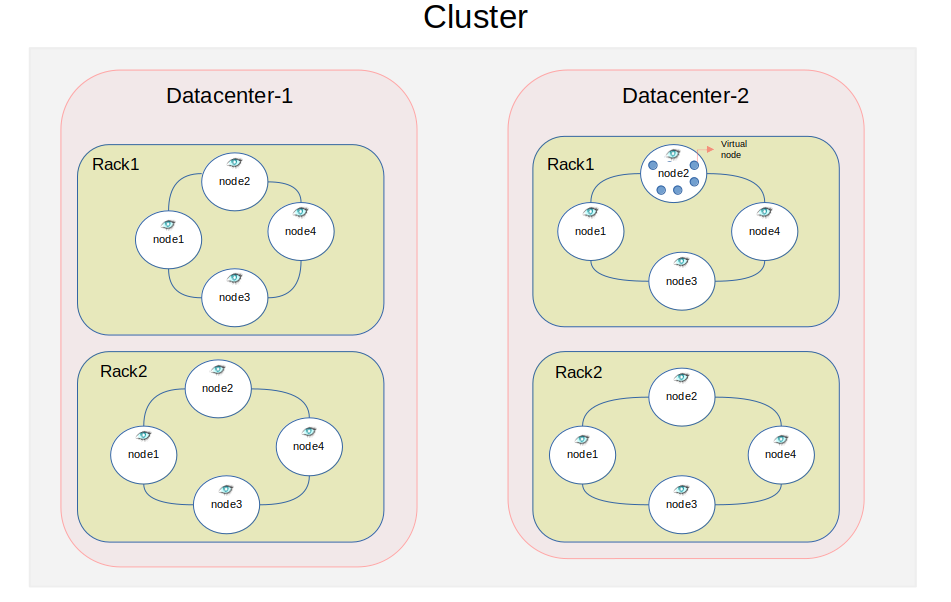 1 Cluster Cassandra System Example
1 Cluster Cassandra System Example
The servers running instances in Cassandra are known as Nodes. A Node is the fundamental infrastructure component of Cassandra. It can be a physical server, an EC2 instance, or a virtual machine. All nodes are organized in a ring network topology, forming a peer-to-peer structure where each node is independent and plays an equal role within the ring. Importantly, each node contains the actual data and is capable of handling both read and write requests. This means that regardless of where the data is stored within the cluster, you’ll always receive the most up-to-date version. Last but not least, each node has virtual nodes.
“Vnodes change this paradigm from one token or range per node, to many per node.”
- Brandon Williams
Nodes are grouped into racks, which are then organized within data centers. One or multiple data centers collectively form a cluster. This hierarchical structure helps optimize data distribution and fault tolerance. Nodes communicate with their neighboring nodes through a protocol known as the Gossip Protocol, which exchanges information about their current status and operability, ensuring all nodes remain aware of each other’s state and activities.
Hinted Hand-off
When an action comes, if the node is unable to respond at that moment, this action is written to a hint file. This file keeps information about the action for a certain period of time. If the node is able to perform the action again within this period, the action information is taken from the file and applied. However, if it is not able to perform the action within this period, the file containing the action information is discarded. This mechanism is called Hinted Hand-off. Thanks to this mechanism, Cassandra ensures consistency at a certain point.
Consistency Levels
Cassandra has tunable consistency. Consistency levels and the rate of consistency can be controlled. There are different forms of consistency for Writing and Reading. There are four levels of consistency for writing:
- One: If any of the replica nodes returns successful, the user returns the result that the action was completed successfully.
- All: If a successful result is returned from all replica nodes, the user returns the result that the action was completed successfully.
- Quorum: In order for the action to be considered successful, the minimum number of successes from the replica nodes is specified. If this number of successful results is returned, the user will be notified that the action was successful.
- Local Quorum: In structures with more than one datacenter, quorum is determined for each datacenter and it is the level of quorum logic.
While the consistency levels in the read state are similar to the write action, they are slightly different. There are three different levels:
- One: The controller node tries to read the data as fast as it can reach among the replica nodes and transmit it to the user.
- All: The result is expected from all replica nodes.
- Quorum: As in writing, a minimum number of successful results are expected. Unlike here, the fastest result is read and the hash is kept. Then the hash of the replicas is taken according to the quorum number. Then all hashes are compared and if the hashes are the same, the first read data is returned.
If the hashes do not match, or if a different result is returned, the most recent timestamp is returned and the outdated data is updated according to the last timestamp.
Replicas & Consistency
The replicas, that is, the copied data in Cassandra, are basically implemented according to two important features. One of them is the replication strategy; If there is only one data center, the Simple Strategy is used, but if there is more than one data center, the Network Topology strategy is used. Another important feature is the replication factor. This factor indicates how many copies will be made of a replica. Also, this feature affects Cassandra’s consistency. In general, if consistency with the quorum is to be ensured, it is recommended to be as follows:
\[Replication \ Factor < Read Quorum + Write Quorum\]
For this, the following values can be used or the quorum number can be adjusted with a formula like below.
| Replication Factor | Read Quorum | Write Quorum |
|---|---|---|
| $N$ | 1 | $N$ |
| $N$ | $N$ | 1 |
| $N$ | $(N+1) / 2$ | $(N+1) / 2$ |
\[\text{quorum} = \left\lceil \frac{\text{sum of all replication factor} + 1}{2} \right\rceil\]
Storage Systems
Data can be stored on disk or memory. Basically, the structures in which we hold the data are:
- Commit log
- Memtables
- SSTables(Sorted String Tables): Index, Summary, Bloom Filters, Data
- Row Cache & Key Cache
In the memory, there are memtables, row cache, key cache, summary of index and bloom filters. On the disk, there are commit log, index table, data table and column bloom filters.
- Commit log: It is the first place where information about the actions to be taken is written.
- Data table: It is the file where the actual data is stored. For each line in the file, there is the time of deletion, the time marked for deletion, and the data in the line. The time marked for deletion keeps the time when the action is given for the first time, the deleted time keeps the time when it is completely deleted. The data is retrieved sequentially from memtables and after this process is finished, the commit log is purged.
- Index Table: It consists of data pairs showing the relevant partition key and the location of this row in the data file.
- Column Bloom Filters: It is a vector formed according to false positive that checks whether the searched column exists for each row. 1 represents existence and 0 represents non-existence.
- Memtables: It is the temporary table where the actions written to the Commit log are written to SSTables before they are flushed. The data stays here until the commit log or memtables is full or until the flush is triggered for memtables.
- Summary of Index: It is a summary file in which the locations of the indexes of the data in the index file and the start and end values of the partition key ranges are matched. For this feature, indexes are taken at certain intervals. This property can be configured with the index_intervalparameter when creating a column-family
- Bloom filters: Vector that decides whether a key is on disk or not. This vector is generated based on the false positive probability. It can be checked with bloom_filter_fp_chance when creating the column-family and its default value is 0.1. Very high values increase the likelihood bias of non-existent.
- Key Cache: Data is stored in key:valuepairs. While the keys hold the primary keys, the values hold the offset of the row in the data file.
- Row Cache: A certain number of rows are kept as cache. There can be three different parameters; the situation we never held, none; where we give a numeric value where all are kept, all or a certain number of rows are kept.
A node can have a certain number of SSTables. This number was specified with the
min_thresholdparameter when creating the column family. If it occurs more than the specified number of SSTables, then these SSTables are made into a single SSTable by applying compaction operation. SSTable compaction is performed by grouping partition keys and keeping last timestamp data, and if there are tombstones associated with these rows/columns, they are deleted.
Conclusion
“Cassandra is a distributed, decentralized, fault-tolerant, column-based NoSQL database. It is horizontally scalable, low cost, and performs well. It is also a very fast read, open source database alternative for OLAP, and according to the CAP theorem, it is an AP featured database alternative.”